1. 문제 설명
어피치는 카카오톡으로 전송되는 메시지를 압축하여 전송 효율을 높이는 업무를 맡게 되었다. 메시지를 압축하더라도 전달되는 정보가 바뀌지 않도록 하기 위해서, LZE(Lempel-Ziv-Welch) 압축을 구현하기로 했다.
LZW 압축은 다음 과정을 거친다.
- 길이가 1인 모든 단어를 포함하도록 사전을 초기화한다.
- 사전에서 현재 입력과 일치하는 가장 긴 문자열 w를 찾는다.
- w에 해당하는 사전의 색인 번호를 출력하고, 입력에서 w를 제거한다.
- 입력에서 처리되지 않은 다음 글자가 남아있다면 (c), w+c에 해당하는 단어를 사전에 등록한다.
- 두번째 단계로 돌아간다.
압축 알고리즘은 영문 대문자만 처리한다고 할 때, 사전은 다음과 같이 초기화된다.

예를 들어 입력으로 'KAKAO'가 들어온다고 하자.
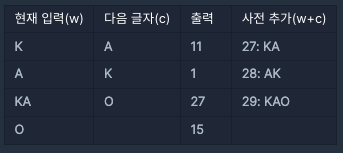
이 과정을 거쳐 다섯 글자의 문자 KAKAO가 4개의 색인 번호 [11, 1, 27, 15]로 압축된다.
문자열 msg에 대해 압축한 결과를 배열로 출력하라.
2. 코드
import string
def find_max_str(msg, index):
max_str = ''
for i in msg:
if max_str + i in index.keys():
max_str += i
else:
return max_str
return max_str
def solution(msg):
keys = [ i for i in string.ascii_uppercase ]
values = [ i for i in range(1, 27) ]
index = { k:v for k, v in zip(keys, values) }
answer = []
while True:
max_str = find_max_str(msg, index)
answer.append(index[max_str])
msg = msg[len(max_str):]
if len(msg) == 0:
break
index[max_str + msg[0]] = len(index.keys()) + 1
return answer
3. 설명
- 우선 사전 초기화를 해주는데, dictionary를 만들 때 문제에서 제시한거랑 다르게 key를 알파벳으로, value는 1부터 26까지로 초기화했다. 이유는 해당 문자(또는 문자열)이 dictionary에 존재하는지 확인하기가 편하기 때문이다.
- find_max_str()으로 사전에 존재하는 최대 문자열을 확인하여, max_str를 반환한다.
msg에 있는 알파벳 하나씩을 더해가면서 dictionary에 있는지 확인하여, 존재하지 않을 때까지의 문자열을 반환한다.
- max_str의 길이를 통해 이후에 조사할 msg를 만들어준다. (msg = msg[len(max_str):])
- 마지막에 max_str + msg[0] 문자열을 dictionary에 추가해준다.

'Algorithm' 카테고리의 다른 글
| 프로그래머스 > 롤케이크 자르기 (Python 3) (1) | 2024.07.24 |
|---|---|
| 프로그래머스 > 모음사전 (Python 3) (1) | 2024.07.23 |
| 프로그래머스 > 게임 맵 최단거리 (Python 3) (6) | 2024.07.16 |
| 프로그래머스 > k진수에서 소수 개수 구하기 (Python 3) (0) | 2024.07.15 |
| 프로그래머스 > [3차] n진수 게임 (Python 3) (1) | 2024.07.14 |