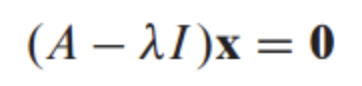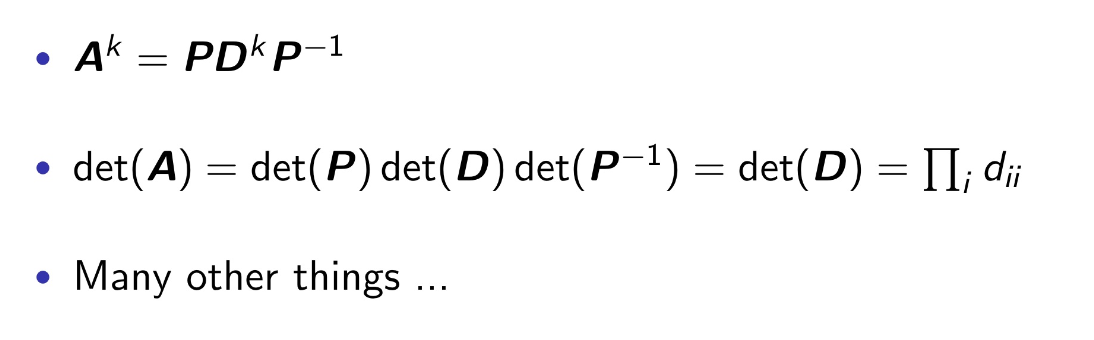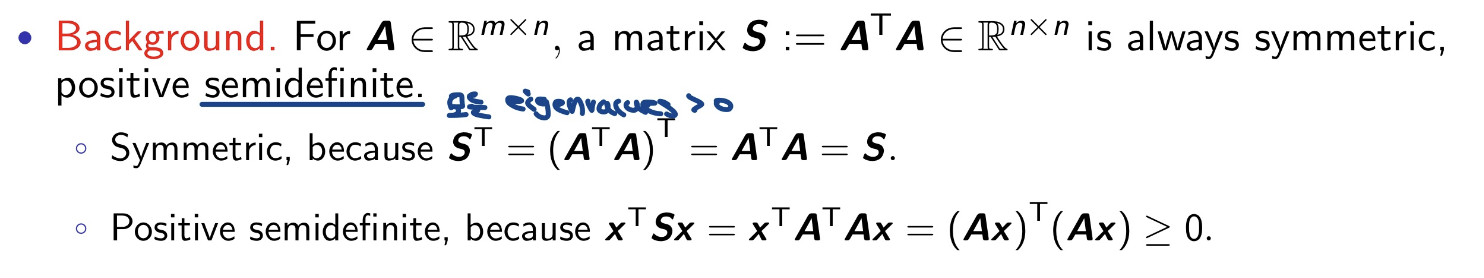LG Aimers에서 연세대학교 정승환 교수님 강의를 듣고 정리한 내용입니다.
틀린 부분이 있다면 댓글 부탁드립니다!
1. 품질의 정의
품질은 10개의 성질로 정의할 수 있다.
(1) 품질의 10가지 성질
- 고객 만족도 : 제품 출시를 앞두고 철저한 사용자 조사를 통해 기능 반영, 높은 만족도 달성
- 일관성 : 동일한 품질의 부품을 만들고, 모든 제품이 동일한 성능과 신뢰성을 유지
- 적합성 : 목적에 적합해야 함. 냉장고는 냉장 기능에 최적화 되어야 함
- 신뢰성 : 제품의 내구성을 높이기 위해 반복적으로 테스트와 개선 작업을 함
- 성능 : 소비자들의 요구를 반영하여 고성능 제품을 개발함
- 안정성 : 품질 검사를 통해 안전하고 믿을 수 있는 제품을 제공함
- 지속 가능성 : 기업, 사회, 환경적 지속 가능한 품질 관리에 앞장섬
- 효율성 : 사용자의 피드백을 반영하여 사용 편의성을 높이고, 처리 속도를 개선함
- 유지 보수성 : 유지 보수가 용이하도록 설계하며, 오랜 기간 동안 품질을 유지함
- 혁신 : 혁신적인 제품을 지속적으로 개발하고 경쟁력을 유지함
(2) 품질 관리 성공 사례 - SAMSUNG
- 첨단 기술 활용 : AI와 머신러닝을 활용한 자동 검사 시스템, IoT를 통한 예측, 유지보수 등을 도입하여 품질 문제를 사전에 예방함
- 전사적 품질 관리 문화 : 모든 직원이 품질 향상에 기여하도록 하는 문화를 구축하여, 전반적인 품질 관리 수준을 높임
- Six Sigma 도입 : 삼성은 1990년대부터 Six Sigma를 도입하여 공급망 관리를 혁신하고, 제품 결함을 줄여 운영 효율성을 극대화함
- 지속적인 개선 노력: 고객 불만 분석, 루트 원인 분석, 성과 지표 추적 등을 통해 지속적으로 품질을 개선해 옴
2. 품질 경영의 발전 과정
(1) 산업혁명과 초기 변화
- 산업 혁명은 대규모 분업을 초래하였고, 작업자들은 제품의 일부분만 담당
- 효율성은 증가했지만, 작업자들이 최종 제품을 확인하기 어려워짐에 따라 품질에 대한 책임이 작업조장에게 넘어감
- 초기 품질 검사는 비계획적이고 불완전하게 수행되어, 품질을 떨어뜨리는 결과를 낳음
(2) 2차 세계대전과 품질관리의 진전
- 2차 세계대전의 영향으로, 품질 관리의 중요성이 증대되었음. 전쟁 중 군수 물자 납품을 빠른 속도로 해야했기 때문
- 샘플링 검사법을 도입하며 품질 보증의 기초를 마련함
- 1950년대 중반에는 품질관리의 영역이 제조 과정에서 제품 설계, 원자재 입고 과정까지 확대됨
- 제품의 전체 라이프사이클을 고려한 품질관리가 시작되었음
(3) 전략적 접근과 현대적 의미
- 1970년대 후반에는 품질보증에서 전략적 품질경영으로 변화함
- 품질이 기업의 장기적인 성공에 필수적 요소로 인식되었음
- 품질은 기업 이익에 직접적인 영향을 미치며, 전사적 노력이 필요함.
3. 품질 표준
(1) ISO 9000 국제 품질 표준

- 국제적 인정 : ISO 9000 시리즈는 전 세계적으로 인정받는 품질 관리 표준임
- 품질관리 절차 : ISO 표준은 품질 관리 절차, 세부 문서, 작업 지침, 기록 유지 장려
- ISO 9001:2015 : 최신 버전은 다른 관리 시스템과의 호환성을 높이는 구조를 따름. risk-based thinking을 강조함
- 글로벌 인증 : 전 세계 201개 국가에서 160만 개 이상의 인증을 받은 글로벌 경영에 필수적인 표준임
(2) ISO 9000 관리 원칙
- 최고 경영진의 리더십
- 고객 만족
- 지속적인 개선 (PDCA, Plan Do Check Act)
- 전 조직 구성원의 참여
- 프로세스 접근법
- 데이터 기반 의사결정
- 시스템적 접근방식
- 상호 이익 공급 관계
(3) 말콤 볼드리지 국가 품질상
- 1988년 미국 정부에 의해 제정됨 : 당시 미국 경제상황은 제 2차 세계대전으로 인해 최악의 상태였음. 한편, 일본의 경제 및 상품경쟁력은 전성기를 맞고 있었는데, 이에 대해 미국은 일본의 경쟁력에 대해 다방면으로 검토함
- Total Quality Management (TQM) 실행을 향상시키기 위해 설계됨
- 국가적 차원의 품질상이 필요함을 인식하고 성과 우수성을 달성한 조직을 인정함
(4) 볼드리지 지표 (Baldridge Criteria)
- 리더십 (120점) + 전략 (85점) + 고객 중심 (85점) + 측정, 분석, 지식 경영 (90점) + 고용 (85점) + 운영 (85점)
- 종합적으로 평가되어 조직의 품질 관리 성과를 판단함
4. 품질 비용
- 목표는 적은 비용으로 높은 품질 얻기!
(1) 품질 비용의 구성요소
- 평가 비용 (Appraisal Costs) : 품질 검사, 테스트 장비 비용 등
- 예방 비용 (Prevention Costs) : 직원 교육, 품질 개선 프로그램, 유지보수 비용 등
- 내부 실패 비용 (Internal Failure Costs) : 재작업 비용, 폐기 비용 등
- 외부 실패 비용 (External Failure Costs) : 고객 불만 처리 비용, 제품 반환 및 교체 비용 등
(2) 품질 비용의 관리 방법
- 평가 비용 : 효율적인 검사 및 테스트 프로세스 도입. 자동화된 검사 시스템 도입으로 오류 최소화
- 예방 비용 : 품질 교육 및 훈련 프로그램을 통해 직원의 품질 인식 향상. 품질 개선 프로젝트를 통해 결함 발생 가능성 감소
- 내부 실패 비용 : 결함 발생 시 신속한 문제 해결과 재작업으로 비용 최소화. 원인 분석을 통해 재발 방지 대책 마련
- 외부 실패 비용 : 고객 피드백 시스템을 통해 문제를 조기에 발견하고 해결. 제품 보증 및 애프터 서비스 강화로 고객 신뢰 유지
5. 품질의 리더