1. 문제 설명
철수와 동생은 롤케이크를 나눠 먹으려고 한다.
두 사람은 롤케이크 길이, 토핑의 개수보다 토핑 종류를 더 중요하게 생각한다.
topping 배열이 주어졌을 때, "동일한 가짓수의 토핑"을 나눠 먹을 수 있도록 하는 방법의 가짓수를 반환하라.
예를 들어, [1, 2, 1, 3, 1, 4, 1, 2] 토핑은 [1, 2, 1, 3], [1, 4, 1, 2] 또는 [1, 2, 1, 3, 1], [4, 1, 2]로 나눌 수 있으므로, 총 2가지이다.
[1, 2, 3, 1, 4]는 어떻게 나누든 공평한 토핑의 종류를 가질 수 없으므로, 0이다.
2. 코드
(1) 1차 시도
def solution(topping):
answer = 0
for i in range(1, len(topping)):
a = topping[:i]
b = topping[i:]
if len(set(a)) == len(set(b)):
answer += 1
return answer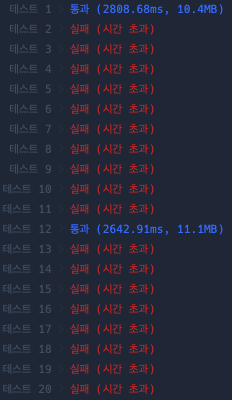
(2) 2차 시도
from collections import Counter
def solution(topping):
topping_dict = Counter(topping)
topping_set = set()
answer = 0
for i in topping:
topping_dict[i] -= 1
topping_set.add(i)
if topping_dict[i] == 0:
topping_dict.pop(i)
if len(topping_set) == len(topping_dict):
answer += 1
return answer
3. 설명
배열 슬라이싱이 $O(N)$이 걸려서, 결국 $O(N^2)$ 수행시간이 걸리게 된다. 그래서 시간 초과가 났던 것이다ㅜ
슬라이싱을 안 하고, 한번의 검토로 기준선 앞, 뒤를 모두 검토할 수 있는 방식으로 다시 코드를 짰다.

Counter dictionary를 사용해서 토핑 종류에 대한 개수를 저장하고, 기준 앞쪽에 대해서 원소를 하나씩 지워나간다.
그러면서 집합에 넣어서 unique한 원소들의 개수를 구한다.
topping_set과 topping_dict 길이가 같다면 answer + 1 해준다.
'Algorithm' 카테고리의 다른 글
| 프로그래머스 > 방문 길이 (Python3) (0) | 2024.08.02 |
|---|---|
| 프로그래머스 > 뒤에 있는 큰 수 찾기 (Python 3) (0) | 2024.07.31 |
| 프로그래머스 > 모음사전 (Python 3) (1) | 2024.07.23 |
| 프로그래머스 > [3차] 압축 (Python 3) (0) | 2024.07.17 |
| 프로그래머스 > 게임 맵 최단거리 (Python 3) (6) | 2024.07.16 |